
实验设备:
- vmware workstation 16 pro
- centos 7
- hadoop 3.3
实验步骤
- 安装centos,先安一台,配置好再克隆两台
- 网络可使用桥接模式,或者NAT模式。需使用静态ip
配置NAT
vmware选择编辑 -> 虚拟网络编辑器 -> NAT模式
取消勾选DHCP
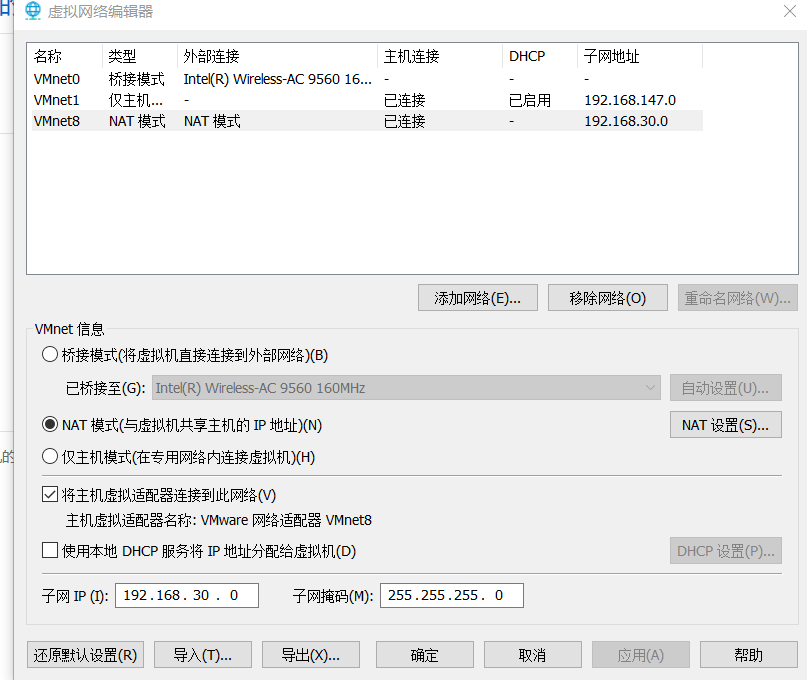
选择NAT设置,查看子网IP,待会设置的虚拟机ip需要跟它一个网段
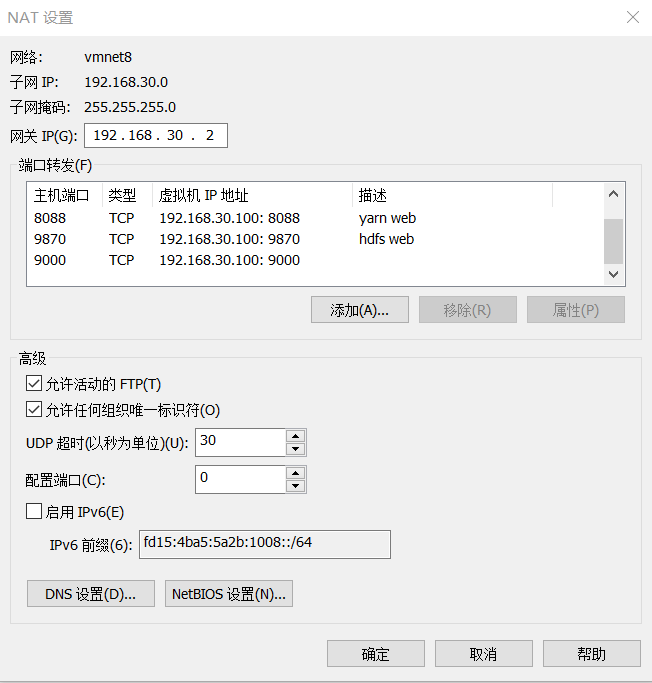
修改虚拟机的网络配置
1
vim /etc/sysconfig/network-scripts/ifcfg-ens33
其中ens33是网卡名字
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=static //静态ip,如果是动态ip写dhcp
DEFROUTE=yes
IPV4_FAILURE_FATAL=yes
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens33 //网卡名字
UUID=41620e18-cab6-4238-bb74-0ceb74b4deab
DEVICE=ens33
ONBOOT=yes //是否开机时启动
IPADDR=192.168.30.200 //静态ip,需要和NAT的子网在一个网段
PREFIX=24 //也可以写 NETMASK=255.255.255.0
GATEWAY=192.168.30.2 //网关需要和NAT设置里网关ip一样
DNS1=8.8.8.8
DNS2=8.8.4.4
重启网络
service network restartping baidu.com此时能上外网了,但是想要和宿主机互相访问还需要看一下网卡的设置。打开windows的网络中心,选择VMnet8这张虚拟网卡,查看其ipv4设置,ip地址需要跟NAT子网一个网段,最后的主机号不能跟虚拟机的主机号相同。
vmware的NAT原理大致如下:虚拟机访问外网通过VMware NAT service这个进程直接跟物理网卡相连,而宿主机访问虚拟机需要通过VMnet8这张虚拟网卡。此外,还有一个VMnet8虚拟交换机,跟VMnet8虚拟网卡不是一个东西。VMnet8虚拟网卡与虚拟机网卡在同一个网段,它们之间通信不需要在网络层进行,只需要在数据链路层。虚拟机和宿主机都是这个网段的一台主机。
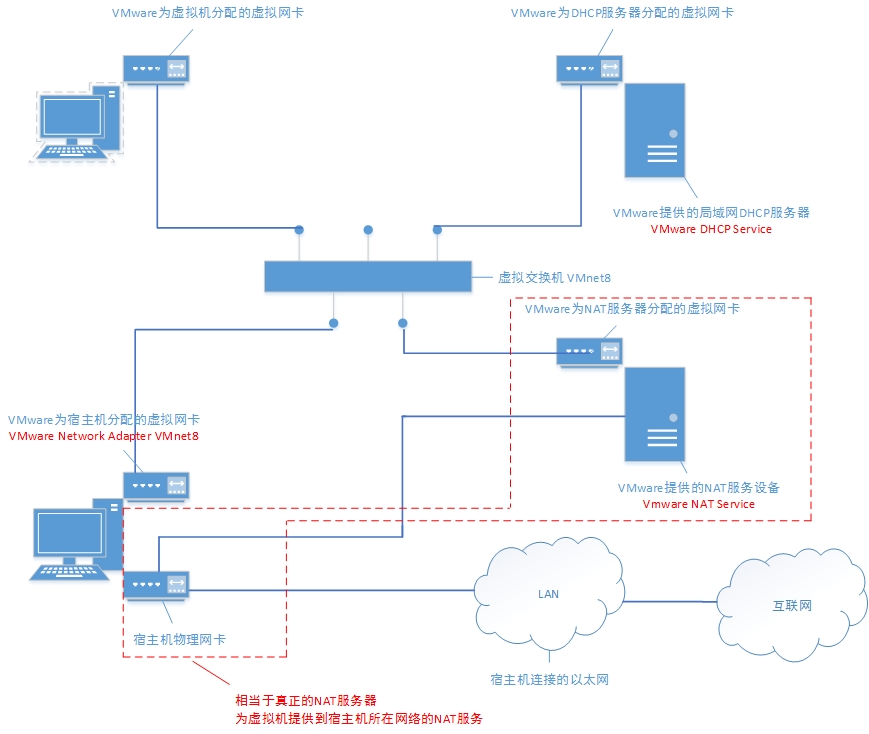
如果虚拟机想要被除了宿主机以外的其他机器访问,需要使用NAT设置里的端口转发。
桥接模式
这个模式设置起来比较简单,注意不能跟其他ip冲突,相当于真实的物理机
关闭防火墙
需要把所有机器的防火墙关闭(还没搞清用到的所有端口,如果搞清了可以只开放部分端口)1
2systemctl stop firewalld
systemctl disable firewalld
设置hosts
设置这个是为了我们能够通过主机名就直接访问机器
设置本机hostname, 名字随便取,注意可读性
hostnamectl set-hostname hserver1
或者1
2vim /etc/hostname
hserver1配置etc/hosts文件
1
2
3
4
5
6[root@hserver1 ~]# vim /etc/hosts
...省略上面内容...
192.168.30.200 hserver1
192.168.30.201 hserver2
192.168.30.202 hserver3
最后加了三行,虽然另外两台机器还没有搭建,可以先写好。
免密登录认证
- 生成公钥,私钥。在A账户下生成那登录的就是A账户
ssh-keygen -t rsa - 进入.ssh目录
cd .ssh - 查看是否有authorized_keys文件,若没有则创建
touch authorized_keys, 并修改权限为600chmod 600 authorized_keys - 追加公钥到authorized_keys
cat id_rsa.pub >> authorized_keys 进行验证
1
2
3ssh localhost
ssh hserver1
ssh 0.0.0.0输入yes后不用输密码就对了
因为用的克隆,所以不用单独设置密钥。如果不用克隆,每台机器需要生成密钥,并且把公钥给对方,自己就可以登录别人的机器。
传输公钥的命令可以用
ssh-copy-id user@host
或者
scp id_rsa.pub hzq@192.168.1.161:/home/hzq
然后还需加入到authorized_keys
安装java与hadoop,配置环境变量
安装java与hadoop省略
修改/etc/profile配置环境变量1
2
3
4
5
6
7
8
9
10vim /etc/profile
最后加上
#java environment
export JAVA_HOME=/opt/apps/jdk
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
#hadoop environment
export HADOOP_HOME=/opt/apps/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
hadoop配置
需要配置$HADOOP_HOME/etc/hadoop/下四个配置文件,core-site.xml, hdfs-site.xml,mapred-site.xml, yarn-site.xml。其中后两个是跟yarn相关,只搭建hdfs可以只配置前两个。
这四个配置文件都有对应的xxx-default.xml
core.site.xml
1 | <configuration> |
hdfs-site.xml
1 | <configuration> |
mapred-site.xml
1 | <configuration> |
yarn-site.xml
1 | <configuration> |
配置hadoop-env.sh
1 | # The java implementation to use. |
还需要在最后加上几个环境变量,因为hdfs默认的账户名是hdfs1
2
3
4
5
6export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export HADOOP_SHELL_EXECNAME=root
配置worker文件
原先叫slaves,此文件用于指定datanode守护进程所在的机器节点主机名1
2
3hserver1
hserver2
hserver3
克隆虚拟机
克隆之后,需要修改hostname和网络地址
- 修改主机名
hostnamectl set-hostname hserver2 - 修改ip
vim /etc/sysconfig/network-scripts/ifcfg-ens33 - 重启网络
systemctl restart network
格式化NameNode
在hserver1上运行 hdfs namenode -format
集群操作
1 | 1. 启动脚本 |
- 启动 stat-dfs.sh
jps查看进程
1
2
3
4
5
6
7
8--1. 在master上运行jps指令,会有如下进程
namenode
datanode
--2. 在slave1上运行jps指令,会有如下进程
secondarynamenode
datanode
--3. 在slave2上运行jps指令,会有如下进程
datanode启动yarn
start-yarn.sh- web查看, 端口分别是9870 (hdfs)和8088(yarn),如果没找到,可以在xxx-site.xml和xxx-default.xml文件中搜一下http看端口号
参考链接
SSH原理与运用(一):远程登录
Hdfs安装模式之完全分布式集群
深入理解VMware虚拟机网络通信原理
