privatestaticfinalinttableSizeFor(int c){ int n = c - 1; n |= n >>> 1; n |= n >>> 2; n |= n >>> 4; n |= n >>> 8; n |= n >>> 16; return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1; }
private static final int tableSizeFor(int c) { - int n = c - 1; - n |= n >>> 1; - n |= n >>> 2; - n |= n >>> 4; - n |= n >>> 8; - n |= n >>> 16; + int n = -1 >>> Integer.numberOfLeadingZeros(c - 1); return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1; }
publicConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel){ if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0) thrownew IllegalArgumentException(); if (initialCapacity < concurrencyLevel) // Use at least as many bins initialCapacity = concurrencyLevel; // as estimated threads long size = (long)(1.0 + (long)initialCapacity / loadFactor); int cap = (size >= (long)MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : tableSizeFor((int)size); this.sizeCtl = cap; }
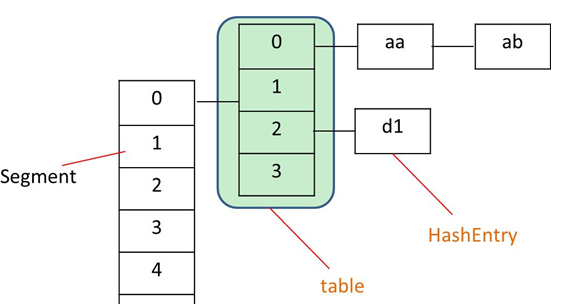
concurrencyLevel:估计同步更新此map的线程个数,帮助初始化容量
long size = (long)(1.0 + (long)initialCapacity / loadFactor):+1为了向上取整
2. put
1 2 3
public V put(K key, V value){ return putVal(key, value, false); }
/** * Base counter value, used mainly when there is no contention, * but also as a fallback during table initialization * races. Updated via CAS. */ //总元素个数,如果有冲突的元素是放到counterCells里 privatetransientvolatilelong baseCount;
/** * Table of counter cells. When non-null, size is a power of 2. */ //存放冲突元素的个数 privatetransientvolatile CounterCell[] counterCells;
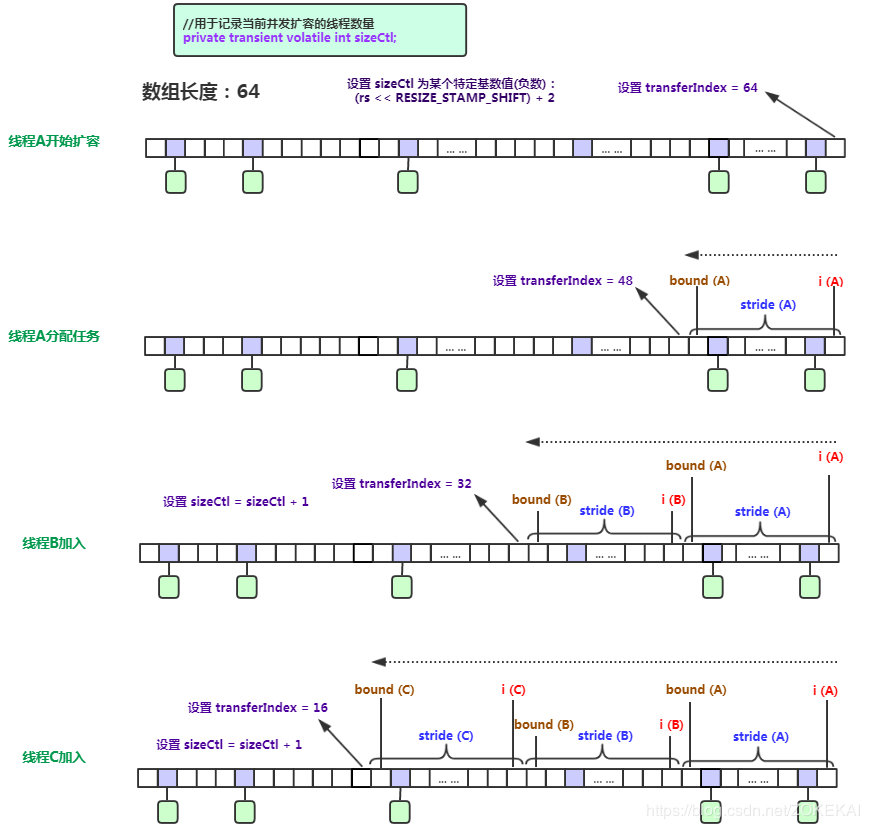
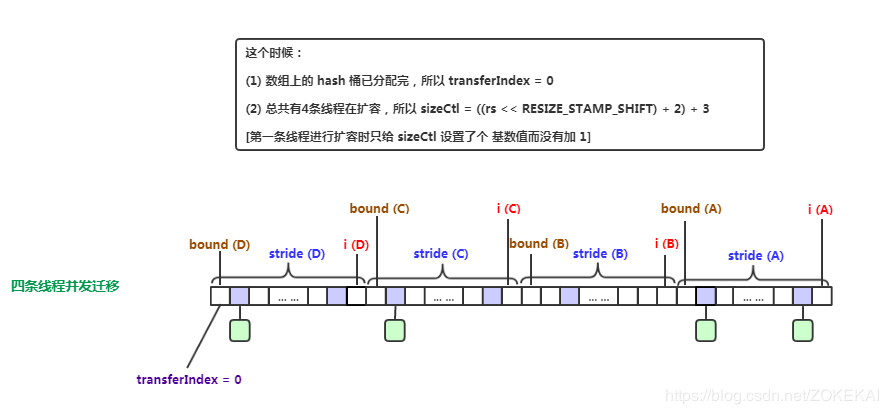
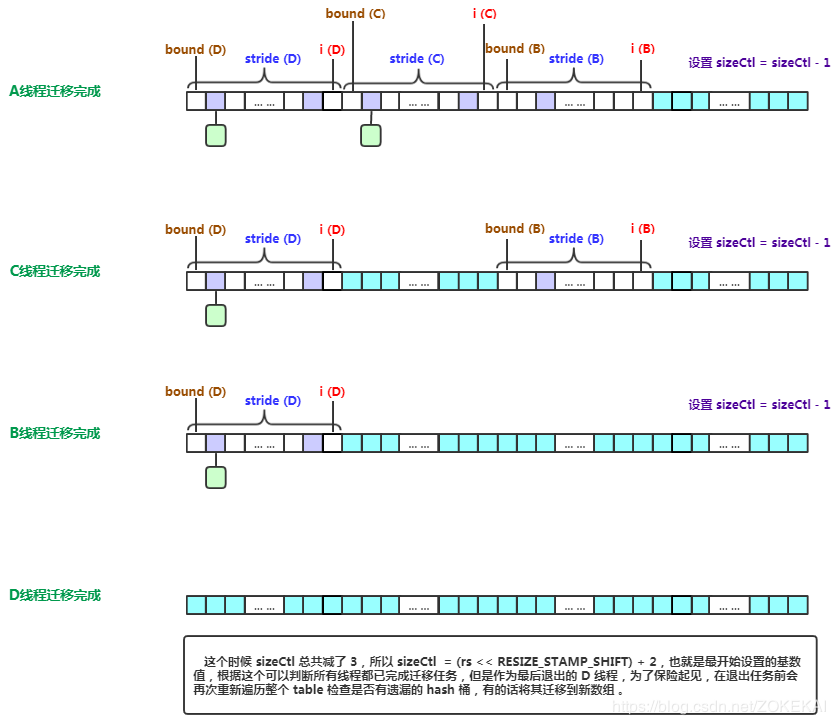
privatefinalvoidaddCount(long x, int check){ CounterCell[] as; long b, s; //cas在if括号里,如果操作成功且counterCells为空,说明没有冲突,直接去下面的逻辑了 //if里面说明有多线程冲突 if ((as = counterCells) != null || //尝试修改baseCount !U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) { CounterCell a; long v; int m; boolean uncontended = true; if (as == null || (m = as.length - 1) < 0 || (a = as[ThreadLocalRandom.getProbe() & m]) == null || !(uncontended = U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) { fullAddCount(x, uncontended); return; } if (check <= 1) return; s = sumCount(); } //在putVal()里一定是 > 0的,check就是binCount if (check >= 0) { Node<K,V>[] tab, nt; int n, sc; //如果上面的sumCount 大于现有的容量的话就触发扩容 while (s >= (long)(sc = sizeCtl) && (tab = table) != null && (n = tab.length) < MAXIMUM_CAPACITY) { int rs = resizeStamp(n); //有线程在扩容 if (sc < 0) { //这里的条件有个bug if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 || sc == rs + MAX_RESIZERS || (nt = nextTable) == null || transferIndex <= 0) break; if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)) transfer(tab, nt); } //注意此处,sc < 0就是这里赋值的 elseif (U.compareAndSwapInt(this, SIZECTL, sc, (rs << RESIZE_STAMP_SHIFT) + 2)) transfer(tab, null); s = sumCount(); } } }
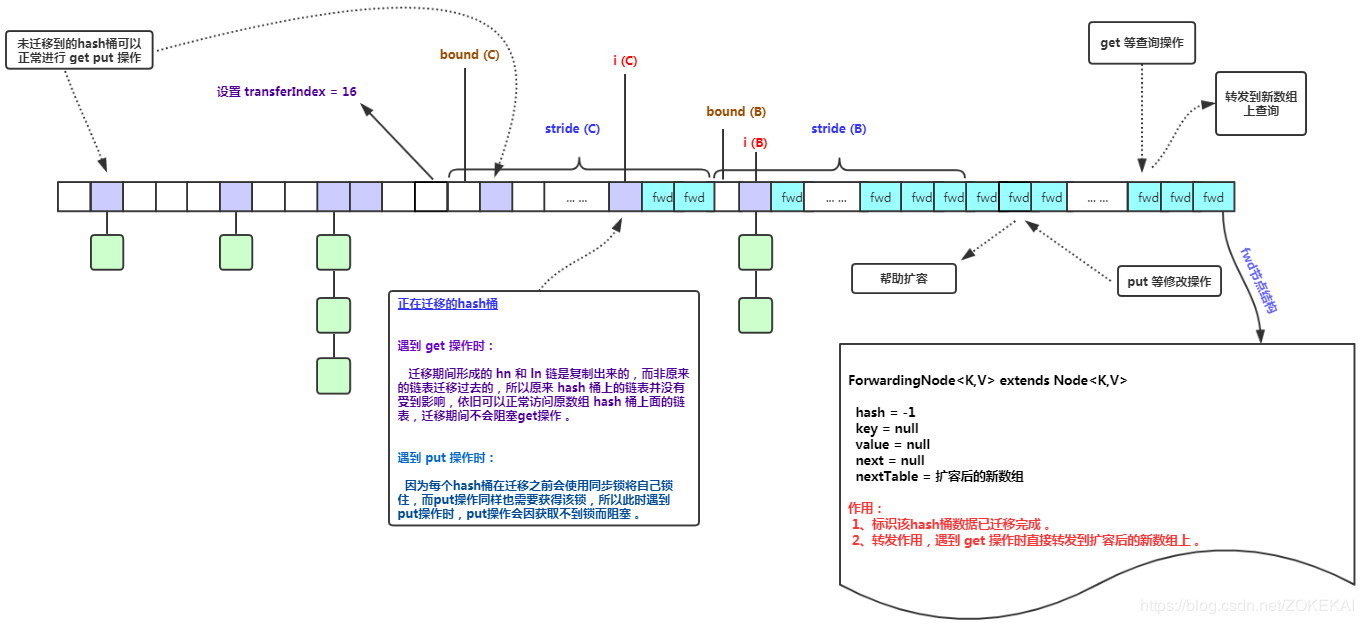
/** * The maximum number of threads that can help resize. * Must fit in 32 - RESIZE_STAMP_BITS bits. */ privatestaticfinalint MAX_RESIZERS = (1 << (32 - RESIZE_STAMP_BITS)) - 1; /** * The number of bits used for generation stamp in sizeCtl. * Must be at least 6 for 32bit arrays. */ privatestaticint RESIZE_STAMP_BITS = 16; /** * The bit shift for recording size stamp in sizeCtl. */ privatestaticfinalint RESIZE_STAMP_SHIFT = 32 - RESIZE_STAMP_BITS; /** * The next table index (plus one) to split while resizing. */ privatetransientvolatileint transferIndex; /** * Helps transfer if a resize is in progress. */ final Node<K,V>[] helpTransfer(Node<K,V>[] tab, Node<K,V> f) { Node<K,V>[] nextTab; int sc;//nextTab:扩容后的table if (tab != null && (f instanceof ForwardingNode) && (nextTab = ((ForwardingNode<K,V>)f).nextTable) != null) { int rs = resizeStamp(tab.length); while (nextTab == nextTable && table == tab && (sc = sizeCtl) < 0) {//正在nextTab上扩容 if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 || sc == rs + MAX_RESIZERS || transferIndex <= 0) break; if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)) { transfer(tab, nextTab); break; } } return nextTab; } return table; }
/** * Returns the stamp bits for resizing a table of size n. * Must be negative when shifted left by RESIZE_STAMP_SHIFT. */ staticfinalintresizeStamp(int n){ return Integer.numberOfLeadingZeros(n) | (1 << (RESIZE_STAMP_BITS - 1)); }
resizeStamp:计算n的前导零的个数(<= 32),并将第16位置为1,结果是 0000 0000 0000 0000 1xxx xxx xxxx xxxx, 左移16位显然为负数(符号位为1)(Must be negative when shifted left by RESIZE_STAMP_SHIFT.)
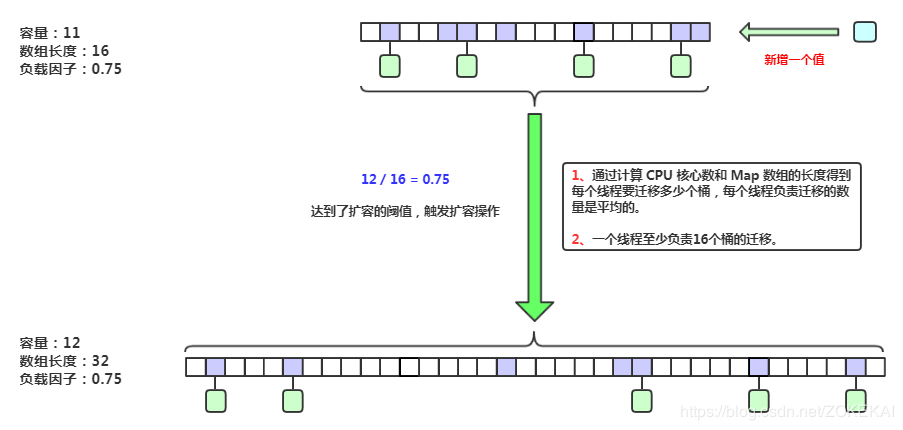
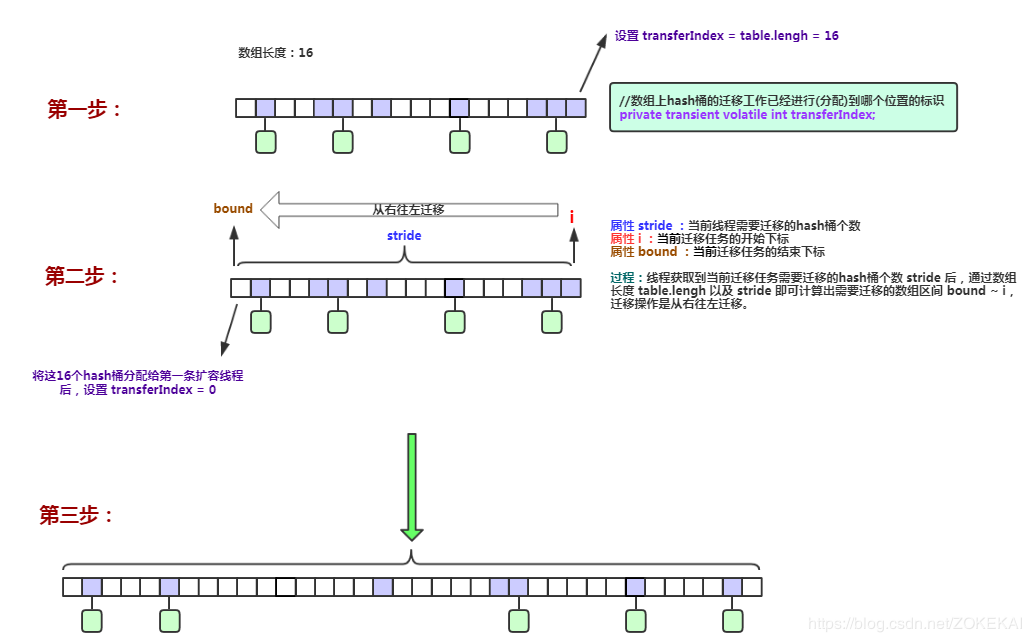
/** * Minimum number of rebinnings per transfer step. Ranges are * subdivided to allow multiple resizer threads. This value * serves as a lower bound to avoid resizers encountering * excessive memory contention. The value should be at least * DEFAULT_CAPACITY. */ privatestaticfinalint MIN_TRANSFER_STRIDE = 16; /** Number of CPUS, to place bounds on some sizings */ staticfinalint NCPU = Runtime.getRuntime().availableProcessors(); /** * The next table index (plus one) to split while resizing. */ privatetransientvolatileint transferIndex;
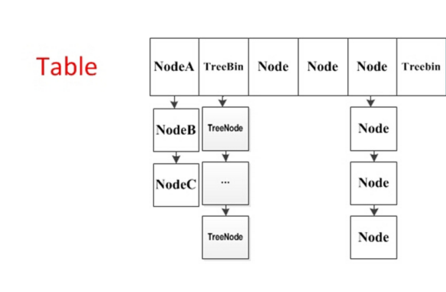
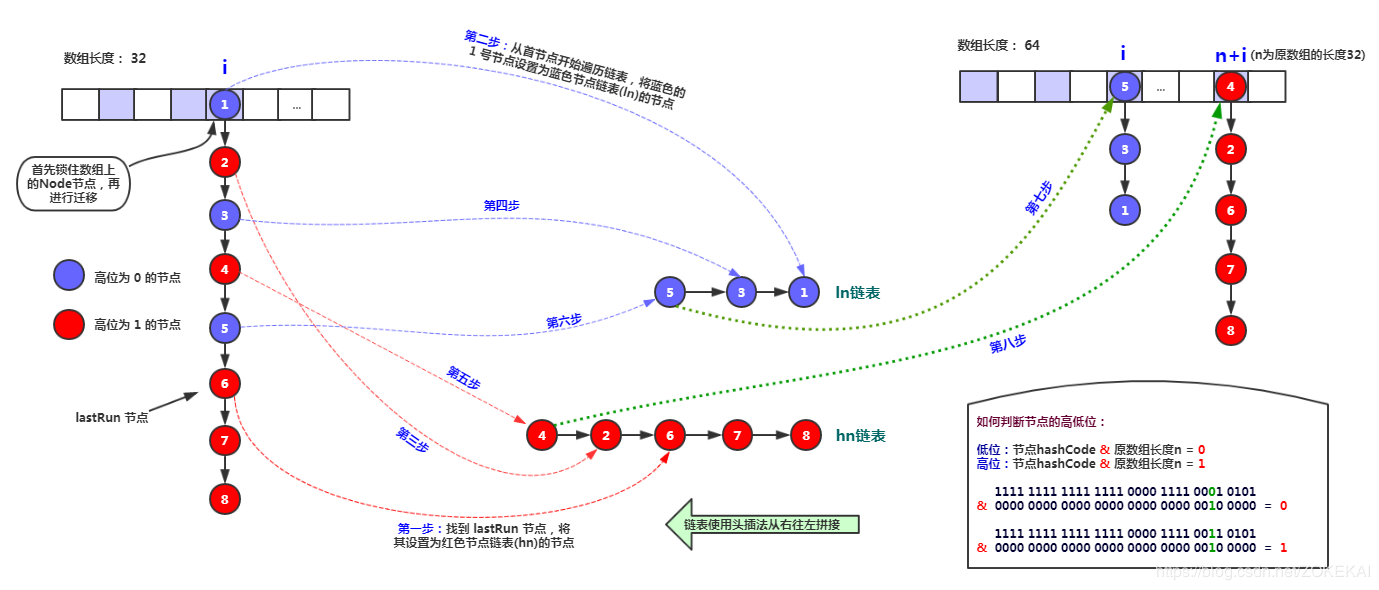
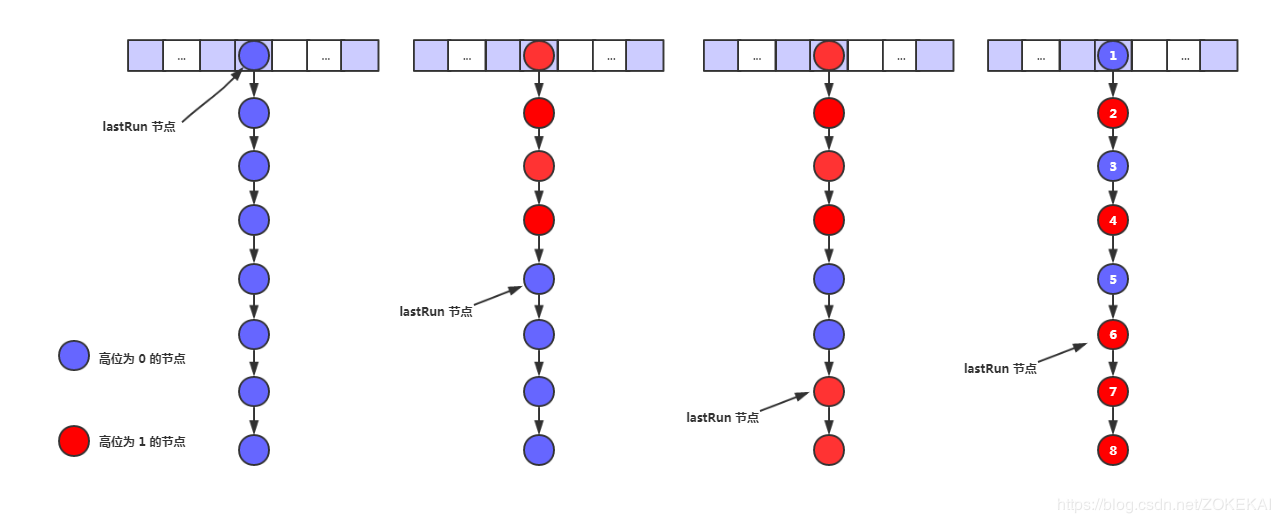
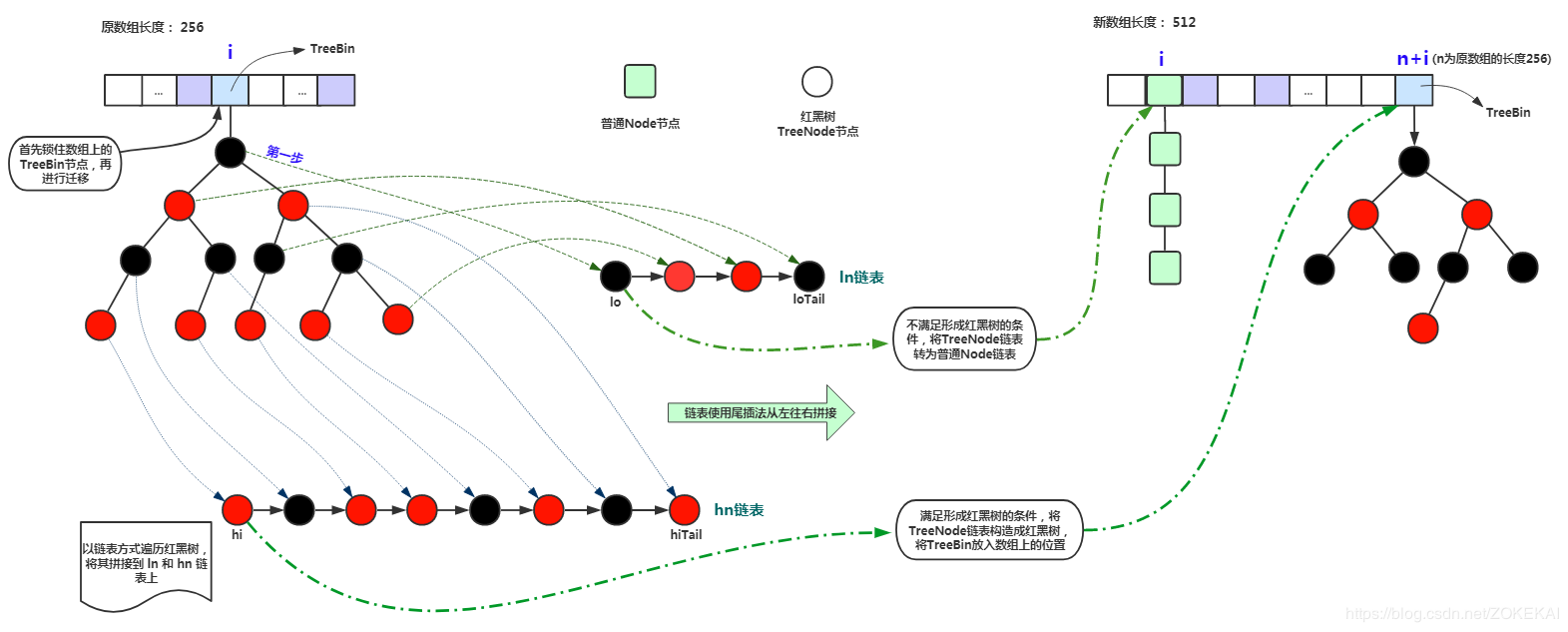
privatefinalvoidtransfer(Node<K,V>[] tab, Node<K,V>[] nextTab){ int n = tab.length, stride; if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE) stride = MIN_TRANSFER_STRIDE; // subdivide range if (nextTab == null) { // initiating try { @SuppressWarnings("unchecked") Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];//每次扩容是 * 2 nextTab = nt; } catch (Throwable ex) { // try to cope with OOME sizeCtl = Integer.MAX_VALUE; return; } nextTable = nextTab; transferIndex = n;//注意此处,transferIndex现在是数组长度 } int nextn = nextTab.length; ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab); boolean advance = true; boolean finishing = false; // to ensure sweep before committing nextTab for (int i = 0, bound = 0;;) { Node<K,V> f; int fh; while (advance) { int nextIndex, nextBound;//本次迁移的范围,下标从nextBound到nextIndex if (--i >= bound || finishing) advance = false; elseif ((nextIndex = transferIndex) <= 0) { i = -1; advance = false; } elseif (U.compareAndSwapInt (this, TRANSFERINDEX, nextIndex, nextBound = (nextIndex > stride ? nextIndex - stride : 0))) {//是从后往前分配的 bound = nextBound; i = nextIndex - 1;//i的初始值 advance = false; } } if (i < 0 || i >= n || i + n >= nextn) { int sc; if (finishing) { nextTable = null; table = nextTab; sizeCtl = (n << 1) - (n >>> 1); return; } if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) { if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT) return; finishing = advance = true; i = n; // recheck before commit, 重新检查一遍,从n开始 } } elseif ((f = tabAt(tab, i)) == null) advance = casTabAt(tab, i, null, fwd); elseif ((fh = f.hash) == MOVED) advance = true; // already processed else { synchronized (f) { if (tabAt(tab, i) == f) {//与put时类似,只不过锁住f之后是迁移 Node<K,V> ln, hn; if (fh >= 0) { int runBit = fh & n; Node<K,V> lastRun = f; for (Node<K,V> p = f.next; p != null; p = p.next) { int b = p.hash & n; if (b != runBit) { runBit = b; lastRun = p; } } if (runBit == 0) { ln = lastRun; hn = null; } else { hn = lastRun; ln = null; } for (Node<K,V> p = f; p != lastRun; p = p.next) { int ph = p.hash; K pk = p.key; V pv = p.val; if ((ph & n) == 0) ln = new Node<K,V>(ph, pk, pv, ln); else hn = new Node<K,V>(ph, pk, pv, hn); } setTabAt(nextTab, i, ln); setTabAt(nextTab, i + n, hn); setTabAt(tab, i, fwd); advance = true; } elseif (f instanceof TreeBin) { TreeBin<K,V> t = (TreeBin<K,V>)f; TreeNode<K,V> lo = null, loTail = null; TreeNode<K,V> hi = null, hiTail = null; int lc = 0, hc = 0; for (Node<K,V> e = t.first; e != null; e = e.next) { int h = e.hash; TreeNode<K,V> p = new TreeNode<K,V> (h, e.key, e.val, null, null); if ((h & n) == 0) { if ((p.prev = loTail) == null) lo = p; else loTail.next = p; loTail = p; ++lc; } else { if ((p.prev = hiTail) == null) hi = p; else hiTail.next = p; hiTail = p; ++hc; } } ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) : (hc != 0) ? new TreeBin<K,V>(lo) : t; hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) : (lc != 0) ? new TreeBin<K,V>(hi) : t; setTabAt(nextTab, i, ln); setTabAt(nextTab, i + n, hn); setTabAt(tab, i, fwd); advance = true; } } } } } }